데이터프레임을 사용하다보면 특정 열이나 행을 조회할 일이 많다. 이럴 때 유용하게 사용할 수 있는 기능이 iloc/loc이다. iloc는 행/열의 위치를 기준으로, loc는 행/열의 이름을 기준으로 지정한 행/열의 값을 출력한다.더 나아가 이렇게 조회한 행/열의 정보를 바탕으로 해당하는 셀의 값을 확인할 수도 있고, 변경이 필요한 경우엔 변경도 할 수 있다.
이 글에서는 자주 쓰이는 iris 데이터셋을 활용해 iloc와 loc의 사용법을 정리해보려고 한다.
1) iris 데이터 불러오기
seaborn 라이브러리는 titanic, iris 등의 다양한 내장 데이터를 제공한다. (제공하는 데이터 이름은 seaborn.get_dataset_names()으로 확인 가능하다.)
이 데이터를 불러와서 사용하는 방법은 간단하다. seaborn 라이브러리를 import한 뒤, load_dataset('dataset_name')을 입력하면 된다. 여기서는 이 글에서 사용할 iris 데이터를 불러오겠다.
import pandas as pd
import seaborn as sns
df = sns.load_dataset('iris')
df.head()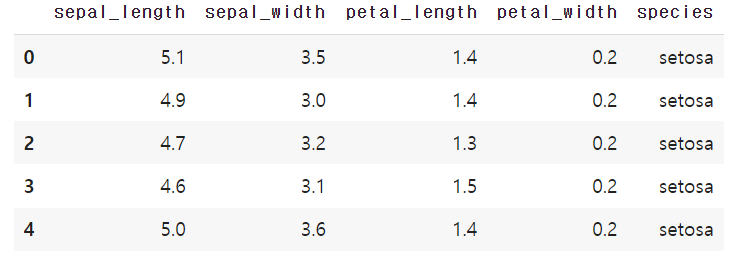
다섯 개의 특성을 갖는 iris 데이터를 불러왔다. 이제 이 데이터셋을 활용해 iloc와 loc를 사용해보겠다.
2) iloc
iloc는 조회하고자 하는 행/열의 위치를 [ ] 안에 입력하면 입력한 위치의 행/열의 값을 반환한다.
헹과 열의 값은 [ ] 안에서 콤마(,)를 기준으로 구분된다. 콤마 앞에 있으면 행, 뒤에 있으면 열을 의미한다.
행만 조회하고 싶을 때는 대괄호 안에 조회하고자 하는 행의 위치를 나타내는 정수만 입력하면 된다. 하지만 열을 조회할 때는 행 부분을 전체 행을 뜻하는 ':'을 입력하고 콤마 뒤에 조회하고자 하는 열의 위치를 나타내는 정수를 입력해야 한다. 특정 행-열의 값을 보고 싶다면 행과 열의 위치를 콤마를 기준으로 앞 뒤로 입력하면 된다.
df.iloc[0] # 첫 번째 행 (출력된 값)
df.iloc[1] # 두 번째 행
df.iloc[:,0] # 첫 번째 열
df.iloc[:,1] # 두 번째 열
df.iloc[0,0] # 첫 행 첫 열의 값
df.iloc[2,4] # 세 번째 행 네 번째 열의 값

여러 범위의 행이나 열을 보고싶은 경우도 있다. 그럴 때는 ':'를 사용해서 범위를 지정할 수 있다. 범위는 콜론(':')을 통해 지정한다.
df.iloc[:5] # 0~4 행
df.iloc[3:8] # 3~7 행
df.iloc[,2:] # 2~끝 열
df.iloc[,1:3] # 1~2 열
df.iloc[22:25, 1:4] # 22~24 행의 1~3열 (출력)
이때 흥미로운 건 하나의 행/열을 반환할 때는 시리즈 형식으로 반환하는 반면, 두 개 이상부터는 데이터프레임 형식으로 반환한다는 사실이다.
연속되는 범위가 아닌 경우에도, 리스트 형태에 입력하여 조회할 수 있다.
df.iloc[[0, 3, 6]] # 1, 4, 6번째 행
df.iloc[: , [1, 3, 4]] # 2, 4, 5번째 열
df.iloc[[0, 3, 6], [0, 2, 4]] # 1, 4, 7번째 행의 1, 3, 5번째 열마지막으로, iloc 안에 행/열의 위치값을 가진 변수를 입력할 수도 있다. 특정 정수나 정수의 리스트를 변수로 지정한 뒤 iloc에 입력하면, 변수로 정의된 값에 위치한 행 또는 열을 반환한다.
n = 3
df.iloc[n] # 4 번째 행을 출력
index_list = [1, 2, 4]
column_list = [0, 2]
df.iloc[index_list, column_list]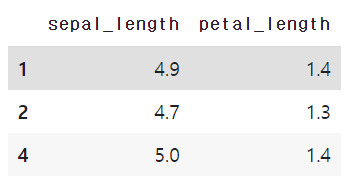
3) loc
loc는 위치값이 아니라 행/열에 지정된 이름을 전달받는다.
index 번호와 이름을 혼동하지 않게, 편의상 위치한 행의 번호에 따라 간단한 ID를 부여하였다.
df['ID'] = [f'ID_{x}' for x in range(len(df))]
df = df.set_index('ID')
df.head()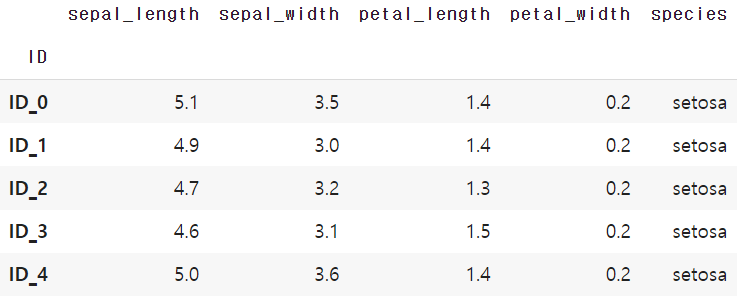
이제 부여한 ID 값을 활용해 loc에 입력해보자.
df.loc['ID_0'] # iD_0 행 출력
df.loc['ID_10'] # iD_10 행 출력
df.loc[:, 'sepal_length'] # sepal_length 열을 출력
df.loc[:, 'species'] # species 열을 출력
df.loc['ID_0', 'species'] # ID_0 행의 species 열을 출력입력 방식은 iloc와 동일하지만, iloc와 다르게 loc는 행 또는 열의 이름을 직접 입력해서 사용하는 것을 확인할 수 있다.
마찬가지로 iloc에서 사용했듯, 범위를 지정하거나 변수를 넣어서 사용할 수도 있다.
df.loc['ID_0':'ID_3'] # 'ID_0'행부터 'ID_3' 행까지 출력
df.loc[:'ID_2'] # 첫 행부터 'ID_2'행까지 출력
df.loc[:, 'sepal_width':'petal_width'] # 'sepal_width'열부터 'petal_width' 열까지 출력
index_names = ['ID_0', 'ID_4', 'ID_64']
df.loc[index_names] # index_names으로 지정된 행 출력
feature_names = ['sepal_width', 'species']
df.loc[:, feature_names] # feature_names으로 지정된 행 출력loc가 iloc와 다른 것이 있다면, 범위를 지정할 때 iloc는 콜론(':') 뒤에 입력되는 위치의 행/열을 포함하지 않고 반환하는 반면, loc는 콜론 뒤에 위치하는 행/열까지 포함한다는 사실이다.
4) 조건에 맞는 행을 조회
이제 더 나아가 loc를 활용해 조건에 맞는 행/열을 찾아보는 방법을 살펴보자.
데이터프레임을 사용하다 보면, 어떤 특성 안에서 특정한 값을 가지고 있는 인덱스를 찾는 경우가 많다.
이때에는 loc의 행의 정보를 입력하는 곳에 찾고자 하는 조건 값을 입력하면 된다.
'petal_length'이 1.6인 iris를 조회해보자.
df.loc[df['petal_length'] == 1.6]
'petal_length' 값이 1.6인 모든 행이 데이터프레임으로 출력된다.
여러 개의 조건을 동시에 입력할 수도 있다.
df.loc[(df['petal_length'] >= 1.8) & (df['petal_length'] <= 2.0)]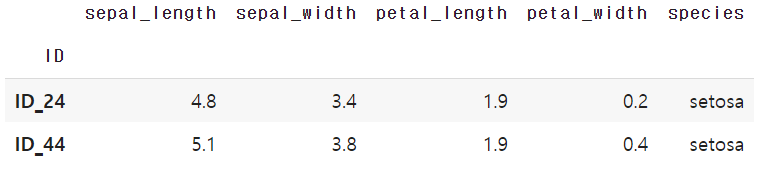
'petal_length'의 길이가 1.8 이상이면서 2.0 이하인 경우는 위와 같이 찾아볼 수 있다. and 조건이기 때문에 두 조건에 '&'를 붙여주었다. ('&' 대신 'and'를 입력하면 ValueError가 나온다.)
마찬가지로 '또는(|)' 조건을 활용할 수도 있다.
df.loc[(df['sepal_width'] == 3.8) | (df['petal_length'] == 1.9)]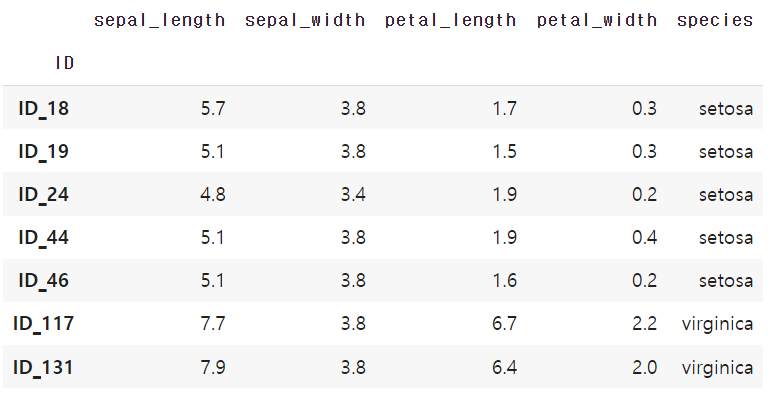
'sepal_width'가 3.8이거나 'petal_length'가 1.9인 데이터프레임이 출력된다.
이렇게 조회한 결과를 활용해 원하는 결과로 변환할 수 있다. 이런 기능은 데이터 전처리 및 특성 공학에서 매우 유용하다!
'Data Analysis' 카테고리의 다른 글
| [Pandas] 자주 사용했던 기능들 정리 - 2. 결측치 처리 (0) | 2022.07.10 |
|---|---|
| [Pandas] 자주 사용했던 기능들 정리 - 1. 데이터프레임 정보 확인하기 (0) | 2022.07.03 |
| [데이터 사이언스] Data Preprocessing(데이터 전처리) & Feature Engineering(특성 공학) (0) | 2022.06.07 |
| [python] Pandas 라이브러리를 활용한 데이터 파일 불러오기 (0) | 2022.06.06 |
| [데이터 사이언스] EDA (Explanatory Data Analysis) (0) | 2022.06.06 |



